用 OpenAI 的 Whisper API 來處理 Telegram 語音訊息
好像沒什麼好說的,就是個接 API 的小練習。值得一提的可能是發現了 ffmpy ,其實裡面就是幫你用 subprocess 呼叫 ffmpeg 指令
import logging
import os
from pathlib import Path
from ffmpy import FFmpeg
from openai import AsyncOpenAI
from telegram import Update
from telegram.ext import (ApplicationBuilder, ContextTypes, MessageHandler,
filters)
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
async def voice_handler(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""Voice message handler."""
if not update.message:
return
message = update.message
# Make sure we have a voice message.
if not message.voice:
await message.reply_markdown('voice_handler: need `message.voice`.', reply_to_message_id=message.message_id)
return
# Download the voice file.
voice_file = await message.voice.get_file()
download_file = await voice_file.download_to_drive()
logger.info("download voice file %s to %s", voice_file, download_file)
# Convert the voice file to mp3. Discard stdout and stderr of ffmpeg.
mp3_file = Path(download_file).with_suffix('.mp3')
with open(os.devnull, 'w') as devnull:
FFmpeg(
inputs={str(download_file): None},
outputs={str(mp3_file): None}
).run(stdout=devnull, stderr=devnull)
logger.info("convert %s to %s", download_file, mp3_file)
# Speech to text.
response = await openai_client.audio.transcriptions.create(
model="whisper-1",
file=open(download_file, "rb"),
language="zh",
)
text = response.text.strip()
await message.reply_text(f'{text}', reply_to_message_id=message.message_id)
# Remove the voice files.
download_file.unlink()
mp3_file.unlink()
if __name__ == "__main__":
application = ApplicationBuilder().token(bot_token).build()
openai_client = AsyncOpenAI(api_key=openai_api_key)
application.add_handler(MessageHandler(filters.VOICE, voice_handler))
application.run_polling()
結果大概就像:
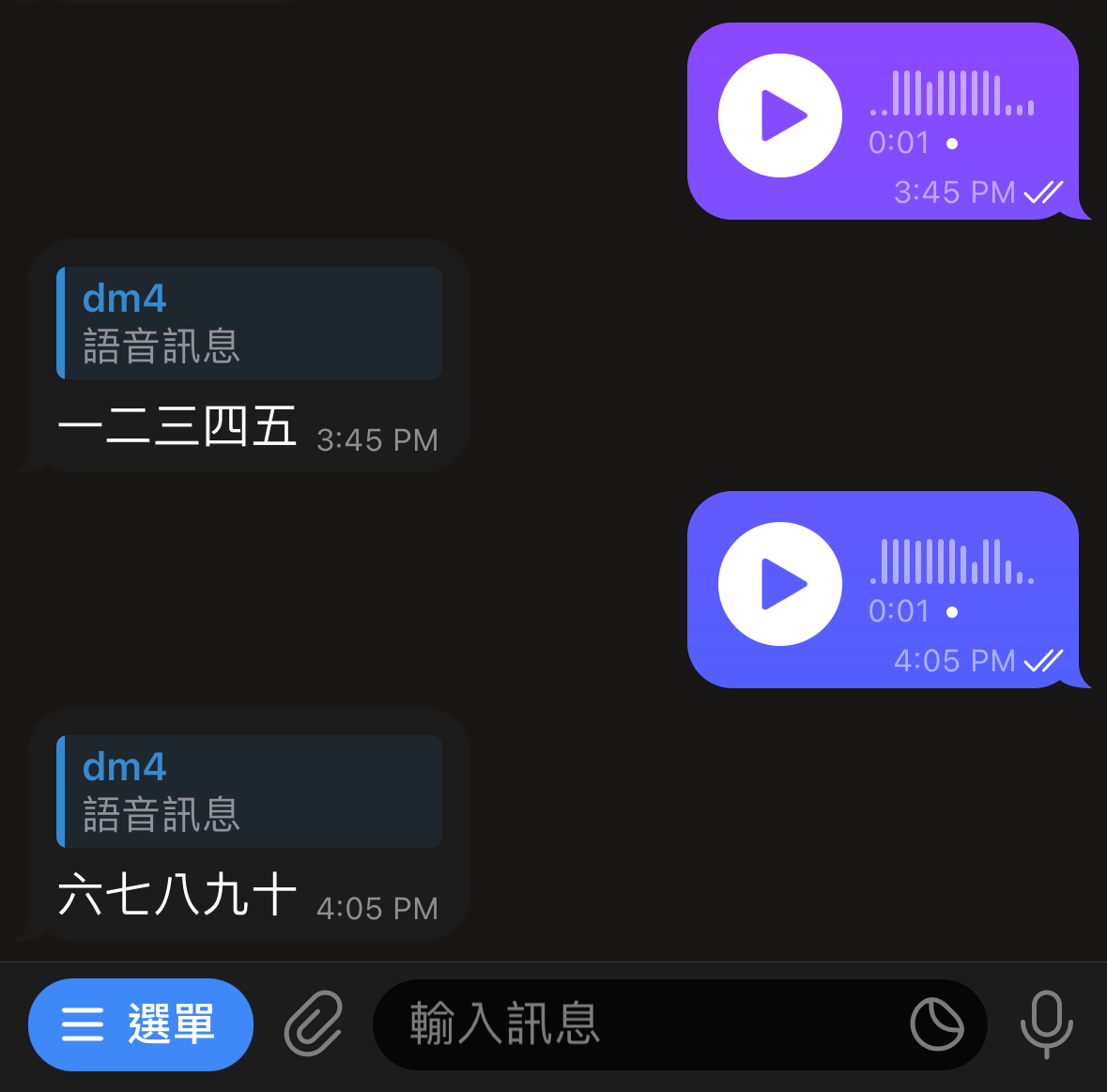
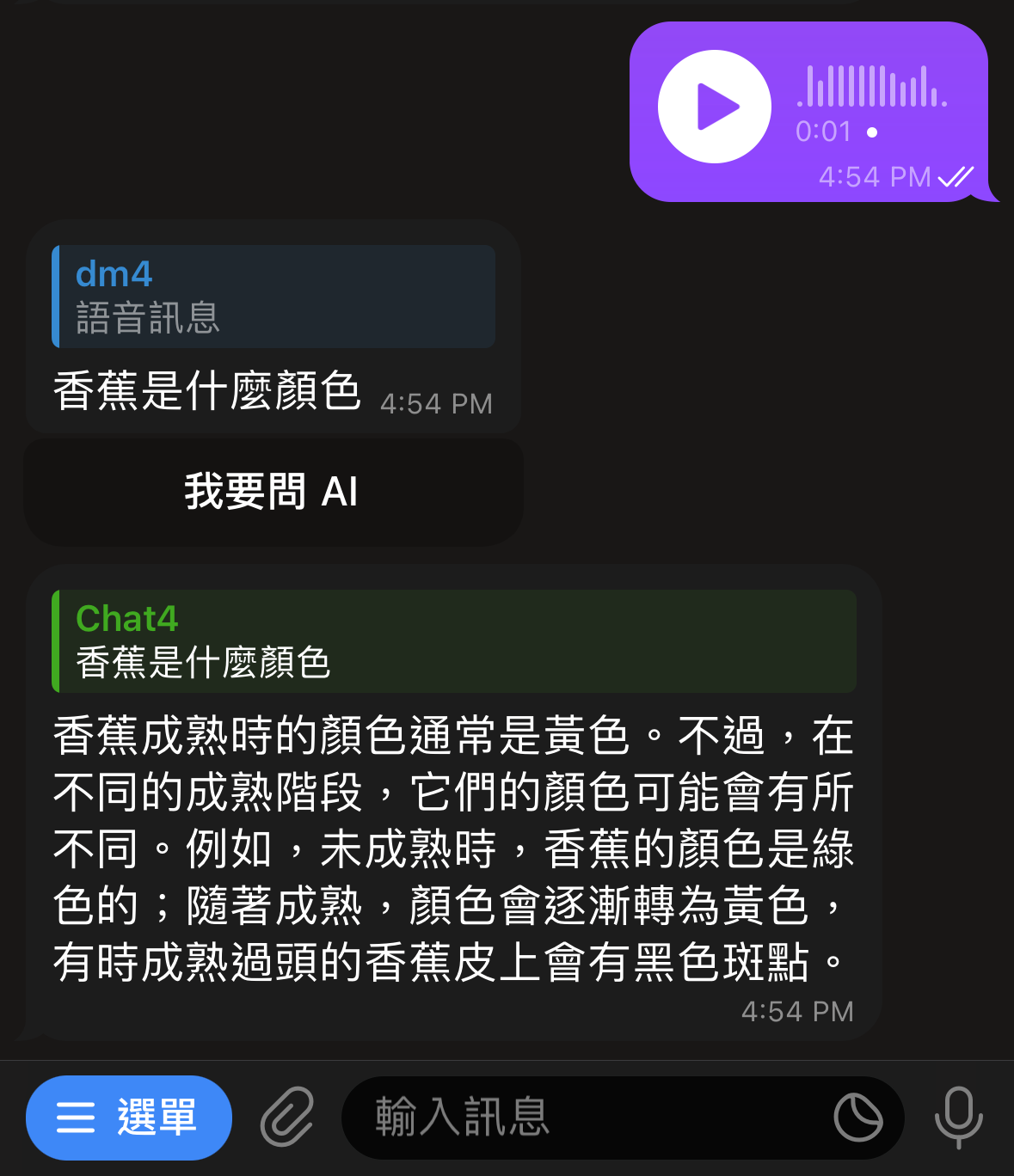
Update: 後來又用 InlineKeyboardMarkup 加了一個按鈕,按下去之後可以直接拿處理完的文字訊息當作問題,拿去問 gpt-4-turbo-preview ,用起來長這樣:
♥ Support Me